This quiz dives deep into the world of Convolutional Neural Networks (CNNs), testing your knowledge from foundational concepts to cutting-edge applications. Whether you’re a seasoned AI expert or just starting your deep learning journey, this interactive experience offers valuable insights and strengthens your understanding of CNNs.
CNN Fundamentals: Building Blocks of Visual Recognition
Ready to test your knowledge of the core components that make CNNs tick? Let’s dive in!
1. What distinguishes a Convolutional Neural Network?
a) It processes sequential data like text.
b) It’s specifically designed for image recognition and other grid-like data.
c) It’s a type of unsupervised learning algorithm.
Answer: b) CNNs excel at processing visual data due to their specialized architecture, which mimics the human visual cortex. Unlike other neural networks, they leverage spatial relationships within images.
2. What is the primary role of Convolutional Layers?
a) Reducing the image size for faster processing.
b) Detecting specific features in the input image using filters (kernels).
c) Connecting every neuron in one layer to every neuron in the next.
Answer: b) Convolutional layers are the heart of a CNN. They scan the image with learnable filters, each specializing in identifying a particular feature like edges, corners, or textures. The stride parameter controls how these filters move across the image.
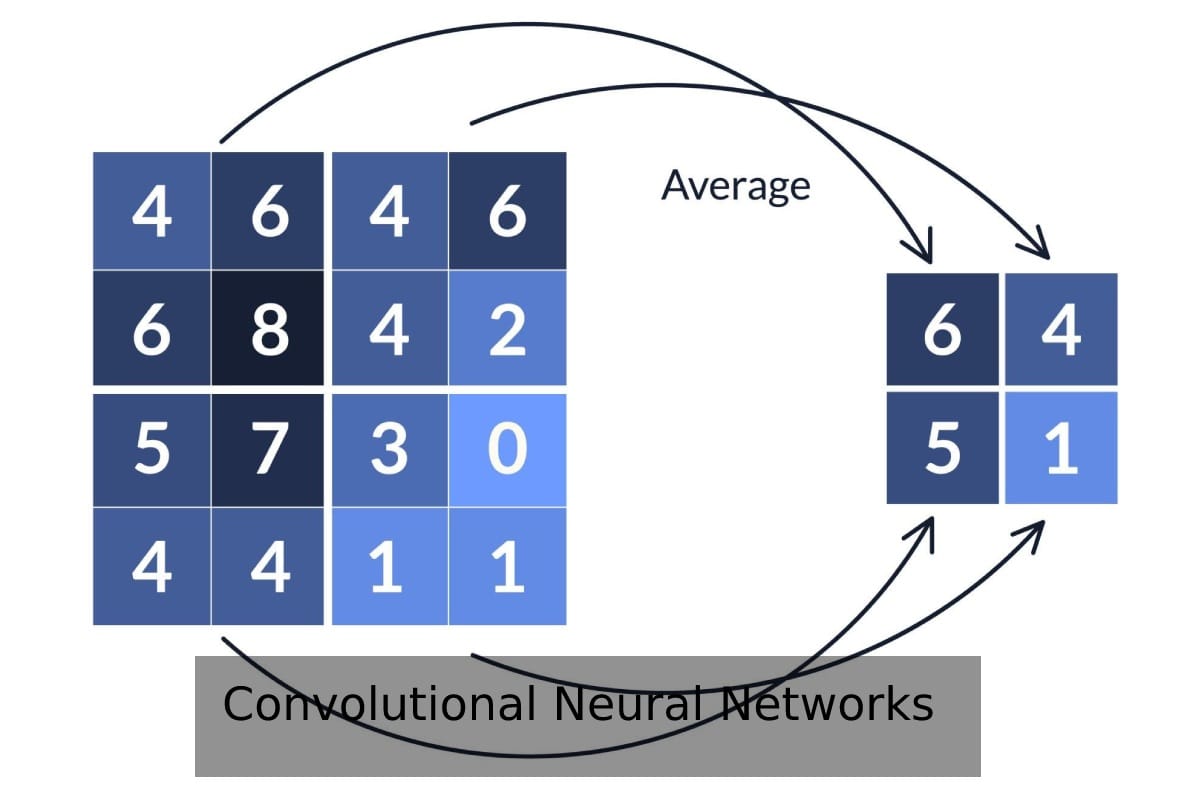
3. How do Pooling Layers contribute to CNN efficiency?
a) They introduce non-linearity into the network.
b) They downsample the feature maps, reducing computational complexity and preventing overfitting.
c) They perform the final classification of the image.
Answer: b) Pooling layers, through techniques like Max Pooling and Average Pooling, shrink the feature maps while preserving the most important information. This not only speeds up processing but also makes the CNN more robust to variations in the input image.
4. What is the significance of Activation Functions in CNNs?
a) They connect all neurons in adjacent layers.
b) They introduce non-linearity, enabling the network to learn complex patterns.
c) They reduce the spatial dimensions of the input.
Answer: b) Activation functions, such as ReLU, Sigmoid, and Tanh, are crucial for introducing non-linearity. This allows CNNs to model complex relationships between features and ultimately make accurate predictions. They act like gatekeepers, determining which neurons should “fire” based on their input.
Advanced CNN Architectures: Pushing the Boundaries
Now that you’ve grasped the fundamentals, let’s explore some sophisticated CNN architectures.
5. What challenge do Residual Networks (ResNets) address?
a) The vanishing gradient problem in deep networks.
b) The computational cost of large convolutional layers.
c) The limitation of fixed-size image inputs.
Answer: a) ResNets introduce “skip connections” that bypass some layers, allowing gradients to flow more effectively during training and mitigating the vanishing gradient problem, which hinders the training of very deep networks.
6. What is the key innovation of Inception Networks?
a) Using multiple filter sizes within a single layer to capture multi-scale features.
b) Reducing the number of parameters to make the network more efficient.
c) Implementing a unique pooling technique to prevent overfitting.
Answer: a) Inception Networks employ multiple filters of varying sizes within the same layer, allowing them to analyze an image at different scales simultaneously, capturing both fine-grained details and broader contextual information.
7. How does Transfer Learning optimize CNN training?
a) It starts the training process from randomly initialized weights.
b) It leverages pre-trained models to accelerate learning on new, related tasks.
c) It trains the network on a very small dataset to avoid overfitting.
Answer: b) Transfer learning allows you to reuse the knowledge gained from training a CNN on a massive dataset (like ImageNet) for a new, similar task. This significantly reduces training time and data requirements.
CNNs in Action: Real-World Applications
Let’s see how CNNs are transforming various fields.
8. Which of the following is NOT a typical application of CNNs?
a) Natural Language Processing
b) Image Recognition and Classification
c) Object Detection and Localization
Answer: a) While CNNs excel in image-related tasks, Natural Language Processing typically relies on different architectures like Recurrent Neural Networks (RNNs) or Transformers.
9. What distinguishes Object Detection from Image Classification?
a) Object detection identifies the objects and their locations within an image.
b) Image classification assigns a single label to the entire image.
c) Object detection only works on grayscale images.
Answer: a) Object detection goes beyond simply classifying the image; it pinpoints the exact bounding boxes around each identified object, providing location information crucial for applications like autonomous driving.
10. What is Image Segmentation?
a) Dividing an image into distinct regions based on object boundaries or other criteria.
b) Enhancing the resolution of an image using deep learning techniques.
c) Converting a color image into grayscale.
Answer: a) Image segmentation creates a pixel-level mask for each object or region of interest within an image, enabling precise analysis in applications like medical imaging or satellite imagery analysis.
Deep Dive and Further Exploration
Is CNN Supervised or Unsupervised?
CNNs are most commonly trained using supervised learning, utilizing labeled datasets. However, unsupervised and hybrid approaches are also emerging, leveraging techniques like autoencoders and Generative Adversarial Networks (GANs). The optimal choice depends on the specific task, available data, and desired performance. coronalt is a great resource for exploring both supervised and unsupervised deep learning techniques.
What technique allows CNNs to process images of varying sizes?
Padding, usually with zeros, is employed to standardize input dimensions for convolutional layers, allowing CNNs to handle images of different sizes. Padding also preserves edge information and controls feature map dimensions.
What is ReLU in CNN?
ReLU (Rectified Linear Unit) is a widely used activation function that introduces non-linearity, speeds up training, and improves performance. However, designers should be aware of the “dying ReLU” problem. Current research explores alternative and improved activation functions for enhanced CNN performance. Understanding weight conversions, such as converting 74.4 kg to pounds, can be helpful when working with datasets involving real-world measurements processed by CNNs.
This quiz offers a glimpse into the world of CNNs. This field is continuously evolving, with ongoing research exploring new architectures, training techniques, and applications. Continuous exploration and learning are key to staying at the forefront of this exciting field!










